Need for speed: making quick LLM calls
September 20, 2024
TL;DR
- We analyzed over 1M LLM calls and found that the length of output is the most critical element in determining how long an LLM takes to respond.
- We found that GPT-3.5-turbo lives up to its name and appears to be much faster than GPT-4. We only have limited data on GPT-4-turbo-preview but it looks OK.
- We found a very small (but significant) difference depending on the length of the prompt. However, it’s such a small difference that any increase in prompt length that leads to a decrease in response length is worth it.
- We found that there are noticeable differences in terms of speed based on the time of day and day of week. If you can shift your queries to ‘off-peak’ hours, you’ll probably see a speed improvement.
Introduction
At Credal, we have a beautiful dataset of well over two million LLM calls [1] and one of the things that we hear most often when talking to our customers is “It’s magic. Sure. But…well, it’s just a bit slow isn’t it? Can you do something about that?”
Last week, the average query through our platform took 12.7s and 3% of the queries took more than 43.06s. You could run 400m in that time! Well, somebody could.
There’s a bunch of advice online based on first principles for how to speed up your LLM processes - but most of those assume that you’re running your own LLM, and I’m going to go out on a limb here and say that, by-and-large, you’re not. Advice on how to get the most (speed) out of existing LLMs is mainly found on the OpenAI forums and excellent blog posts. However, we think that, given our dataset, we should be able to quantitatively answer the question: “How to make a quick LLM call” and so that’s what we’re about to do.
Set up
I don’t want to go all sciencey on you [2], so I’ll keep this as simple as possible. We take our data on how long the LLM takes to complete its task. And for each of those data points, we also take all the things we thought might influence that. Those include:
- The number of input tokens (how long the prompt was)
- The number of output tokens (how long the response was)
- The model used
- The time of day and day of week
Then, we built a simple linear model aiming to predict how long the response would take, based on those inputs. If you’d like more explanation of linear models there are places for you to get that - but alas, they’re not this blog post.
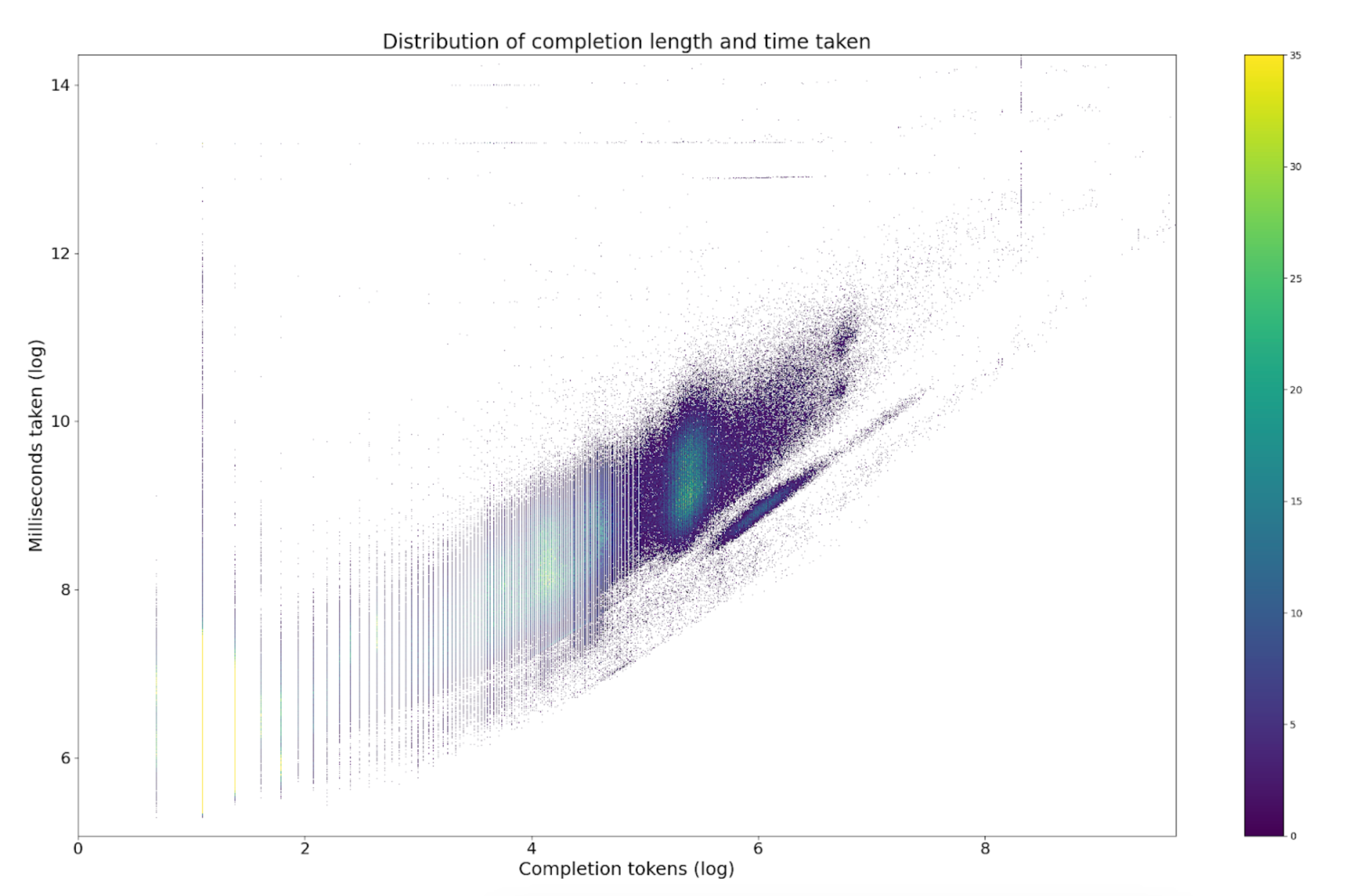
It’s all about the amount of output
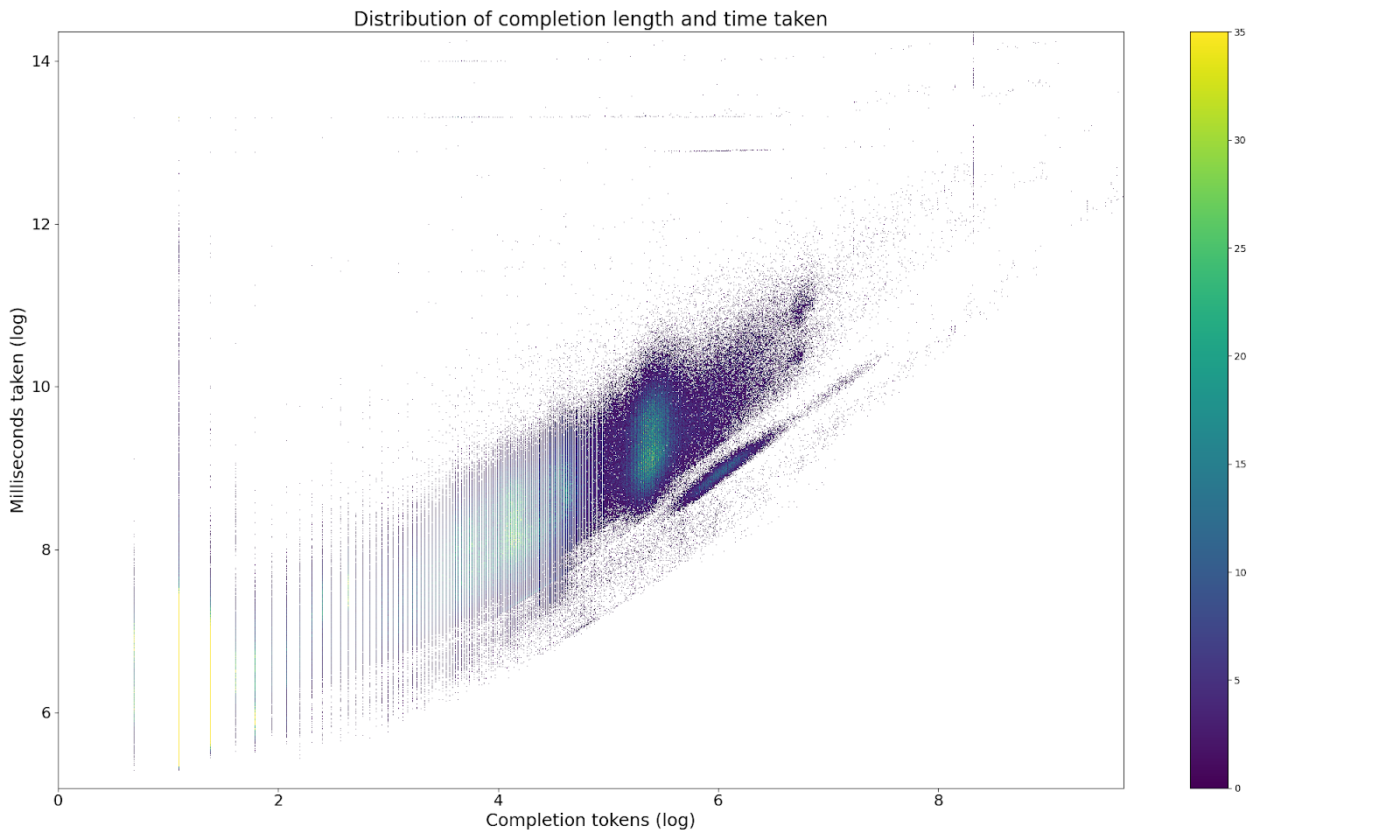
What I hope the above shows is that I know how to plot cool looking graphs. However, if you look a touch deeper you’ll see that there’s actually a really strong link between the time taken and the number of tokens you retrieve. In fact, if you simply build a model looking at only the number of prompt tokens and the number of completion tokens, you find that each prompt token costs you approximately 0.4ms and each completion token costs you approximately 54ms. If you’re optimising for speed and you get the chance to spend 134 tokens on reducing your output tokens by 1, you should do it!
So, lesson number 1: ask yourself if you really really need all those output tokens. If you do, then fine. But if there’s one thing you can do to speed up your LLM calls it’d be to receive fewer output tokens.
What about prompt tokens though?
Do they make a difference?
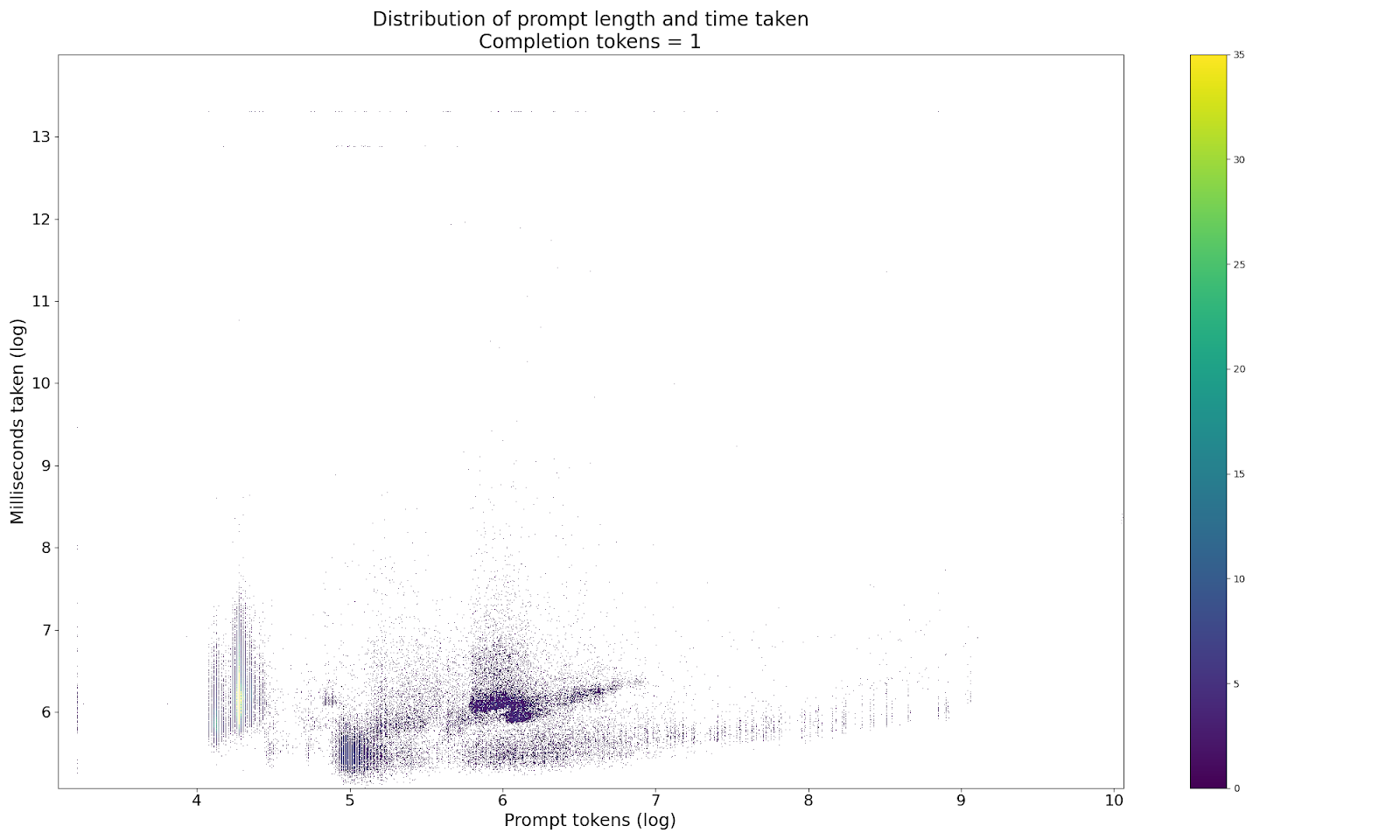
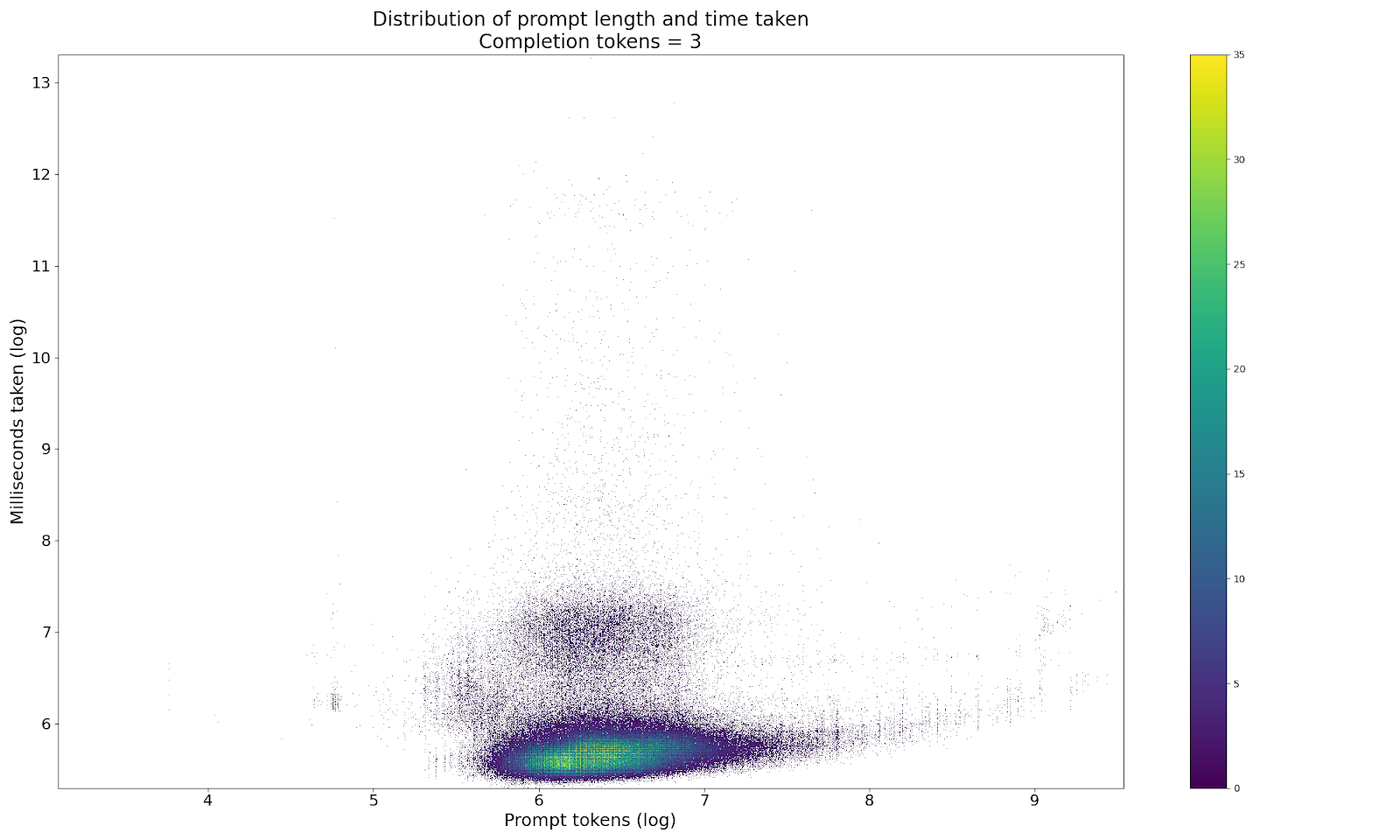
Here, aside from just looking at the coefficients of the linear model (and finding them tiny) we can fix the number of completion tokens and look at how the time taken varies with the number of prompt tokens. These are mainly included because the graph above looks like an aerofoil which is pretty cool. But anyway, if you wanted confirmation that the number of prompt tokens doesn’t really make a difference to the speed of the query, the correlation between prompt length and completion time when fixing the number of completion tokens ranges between -0.02 and +0.01 for completion tokens <= 4. Looking at the longer end of things, completion tokens of 64 gives us a stronger correlation (0.24) but hardly looks conclusive. Might be worth poking about here to see if there are non-linearities at play. But otherwise, don’t stress on the prompt length.
The awkward coefficient
So my advice thus far…use long prompts to generate short responses. However, that belies a nasty little nonlinearity (my nickname at school) - the intercept of our linear equation. Simply put, if I think it takes about 55ms to generate a token, does that mean that the quickest queries are all in the region of 55ms?
Unfortunately, no. The quickest queries we have are around 160ms.
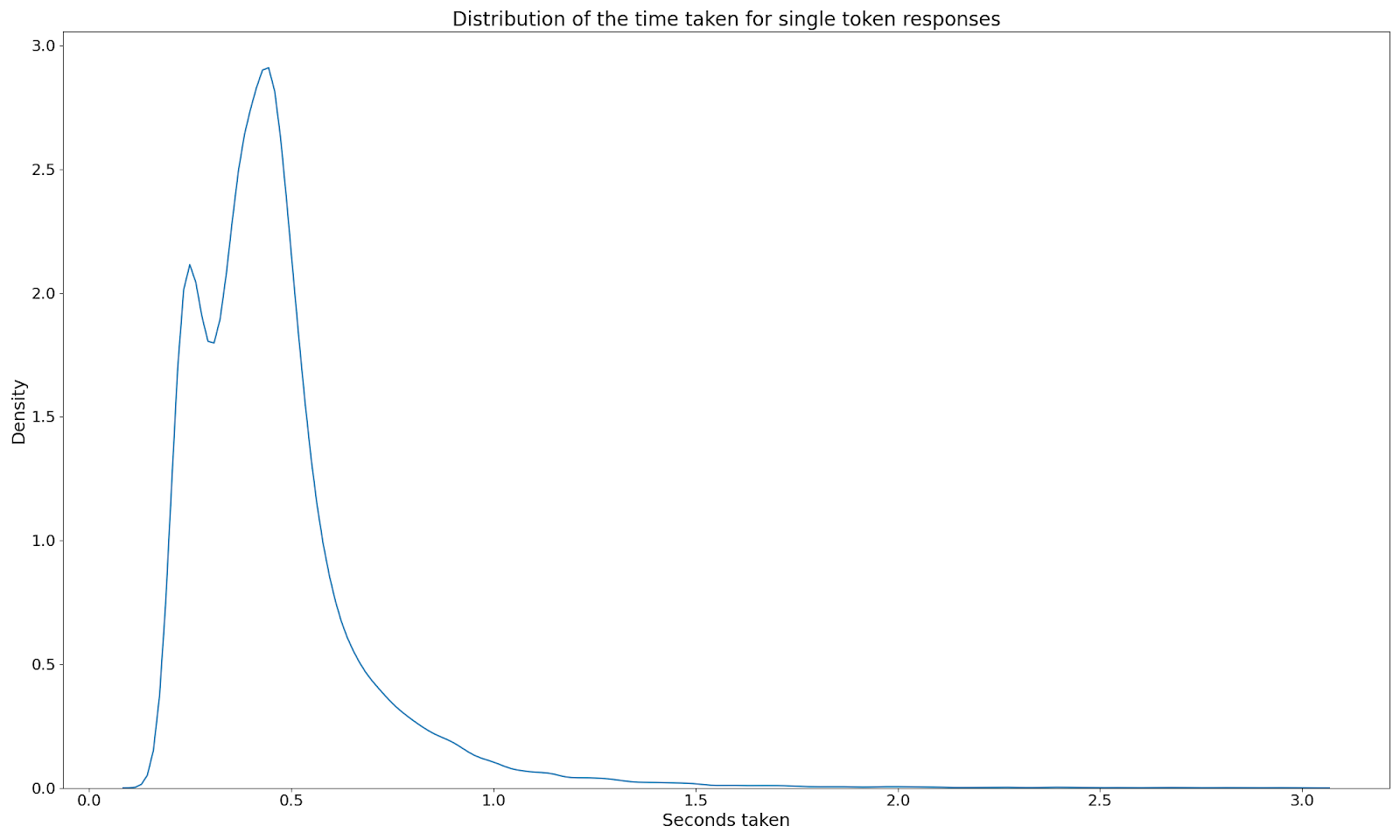
It turns out that there are start-up costs associated with the API call such that, if your query really needs two tokens to answer, you’ll end up with a slower query on average if you split it up into two queries.
Now wait…haven’t we (a royal we…I played no part in it) invented something to do with asynchronicity? Well, yes. So actually, if you can run two 160ms queries simultaneously rather than a single query of 200ms (the quickest we’ve seen a two token query) then your total time will be lower. But I’m not here to talk about synchronicity.
Look at that graph again. Looks weirdly bumpy, doesn’t it? I am absolutely here to talk about weirdly bumpy graphs. Why oh why do we have a bumpy graph?
And this brings us nicely onto our fourth (and probably final) point - choice of model.
Just how turbo is turbo?
I’d say it’s pretty bold bringing out a model called GPT-3.5-turbo. I mean, it’s in the name. But then, it’s also pretty bold to build ChatGPT in the first place (or DALLE, or SORA, or to have a major executive board coup and then overturn it…so perhaps my standards for boldness need to shift).
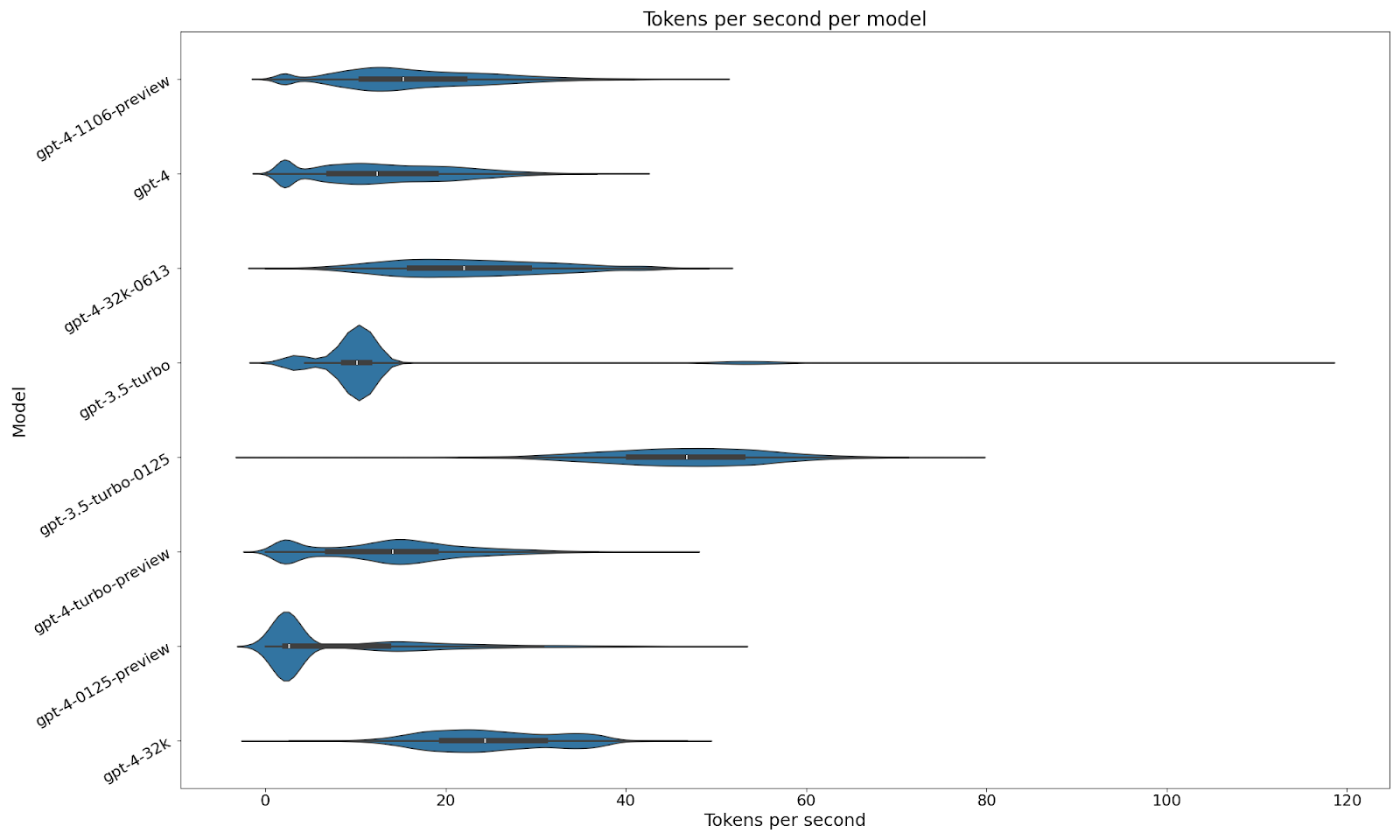
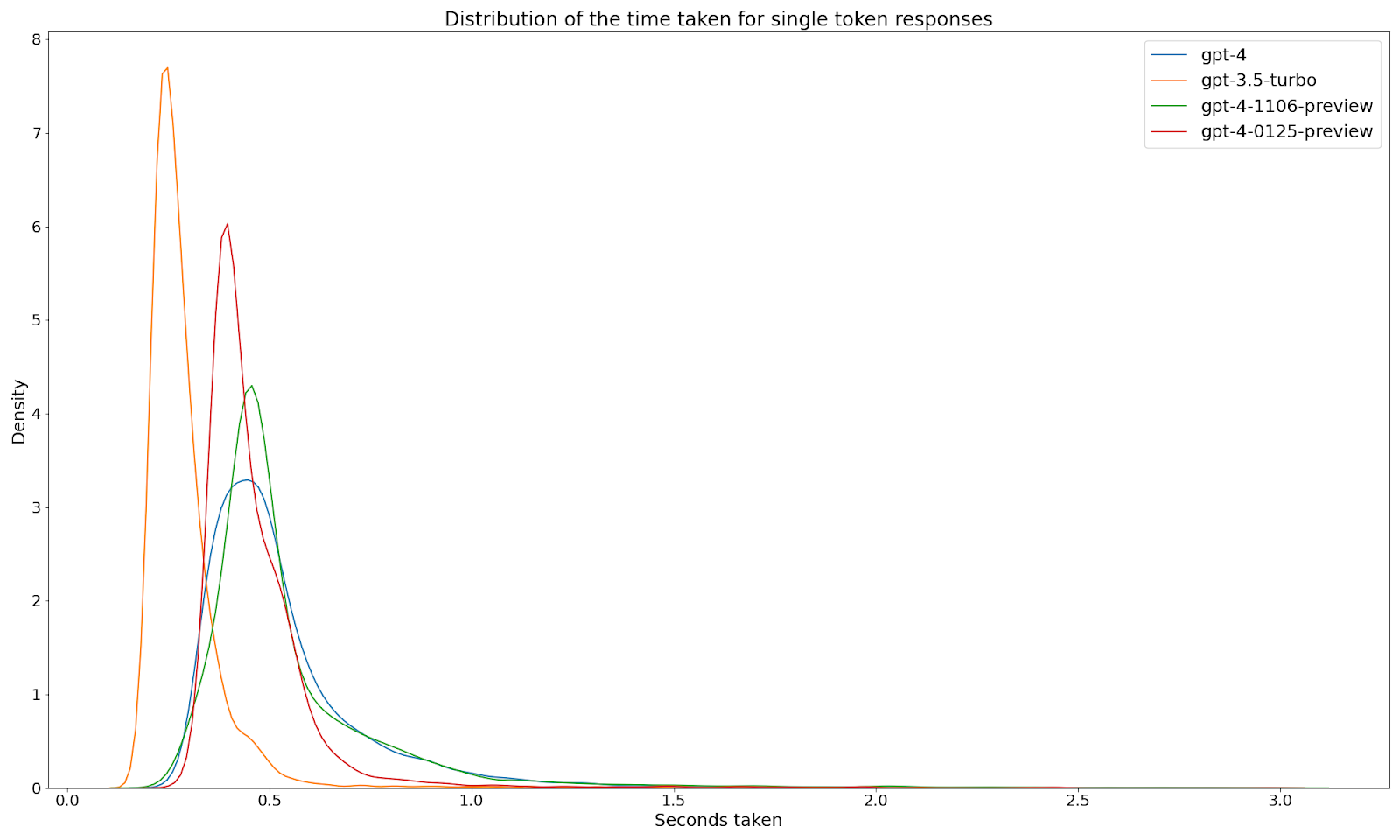
One of the things that's extremely interesting to me about this chart is just how well the gpt-4-32k models perform from a tokens per second perspective.(admittedly at much, much higher cost). Moving from GPT-4 to GPT-4-Turbo might net you an extra one or two tokens per second for normal, 20+ token responses, but moving to GPT-4-32k might get you 10-15 extra tokens per second, on average. Depending on the nature of your chatbot, if the average response length is relatively short say, say, about 100 tokens, then moving from GPT-4 to Turbo is going to move your average completion time from a little over 6 seconds to a little under it. But moving to GPT-4-32k is going to move your average to about 4 seconds.That being said, IIRC OpenAI are planning to move GPT-32k to consume from the turbo endpoints eventually. Now I don't know exactly what you’re getting from this graph, but I want to talk to you about why “tokens per second” might be a misleading metric for you. And it’s basically the start-up cost (that awkward intercept). We have a pretty major use case that results in many many queries giving quite short responses. And those queries all go through gpt-3.5-turbo. So you’ll actually see that GPT-3.5-turbo appears to be one of the slower models.
But that is a lie.
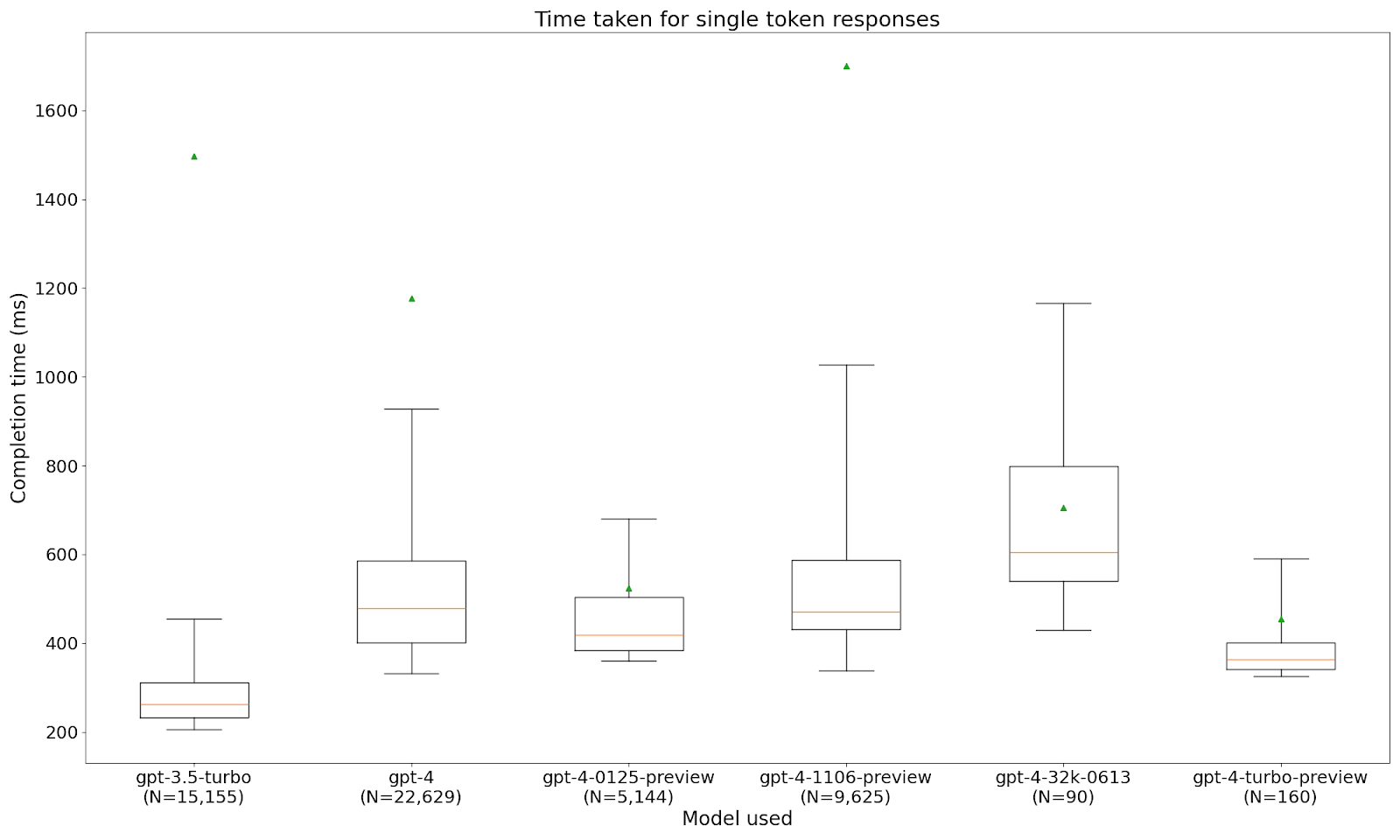
For single token responses, GPT-3.5-turbo is actually the quickest model, consistently outperforming any of the GPT-4 flavours (though it’ll be interesting to see how 4-turbo pans out). Fascinatingly, on this metric, GPT-4-32k - is far slower than gpt-4-turbo, an exact reversal of the metrics we saw before. That suggests that somehow it has slower startup costs, but its throughput on completion tokens is much better than GPT-4-turbo.
Looking at larger responses (100 - 200 tokens) and hence now using tokens per second as a metric…
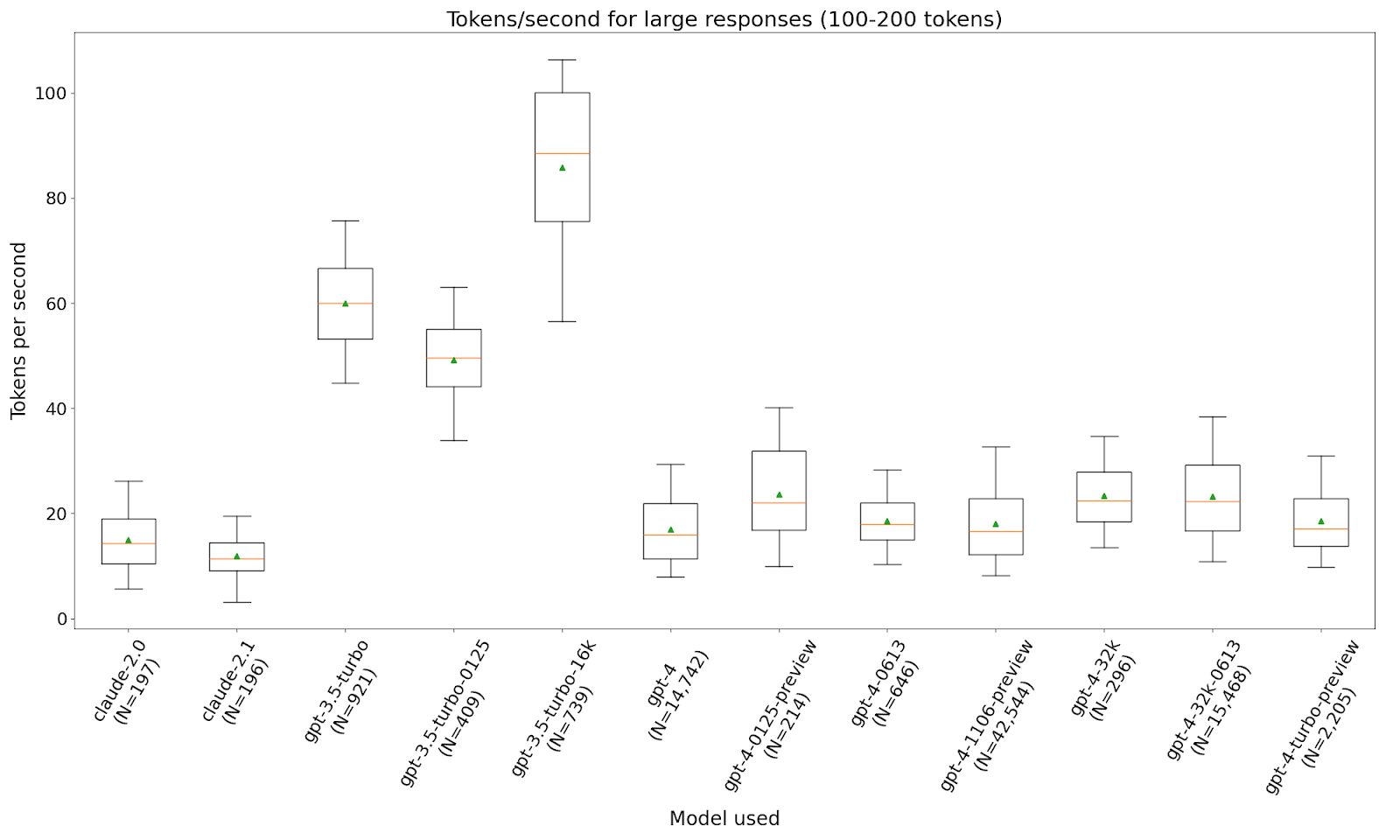
Again, GPT-3.5-turbo stands out as the quickest model to use, and in the GPT-4 family, the 32k models perform much better again
Choosing your time
Now OpenAI have more than one customer so we can’t tell exactly when they have their ‘busy periods’. But we can see when we have our busy periods and fudge it make assumptions that our traffic is representative of theirs. So when do they get busy?
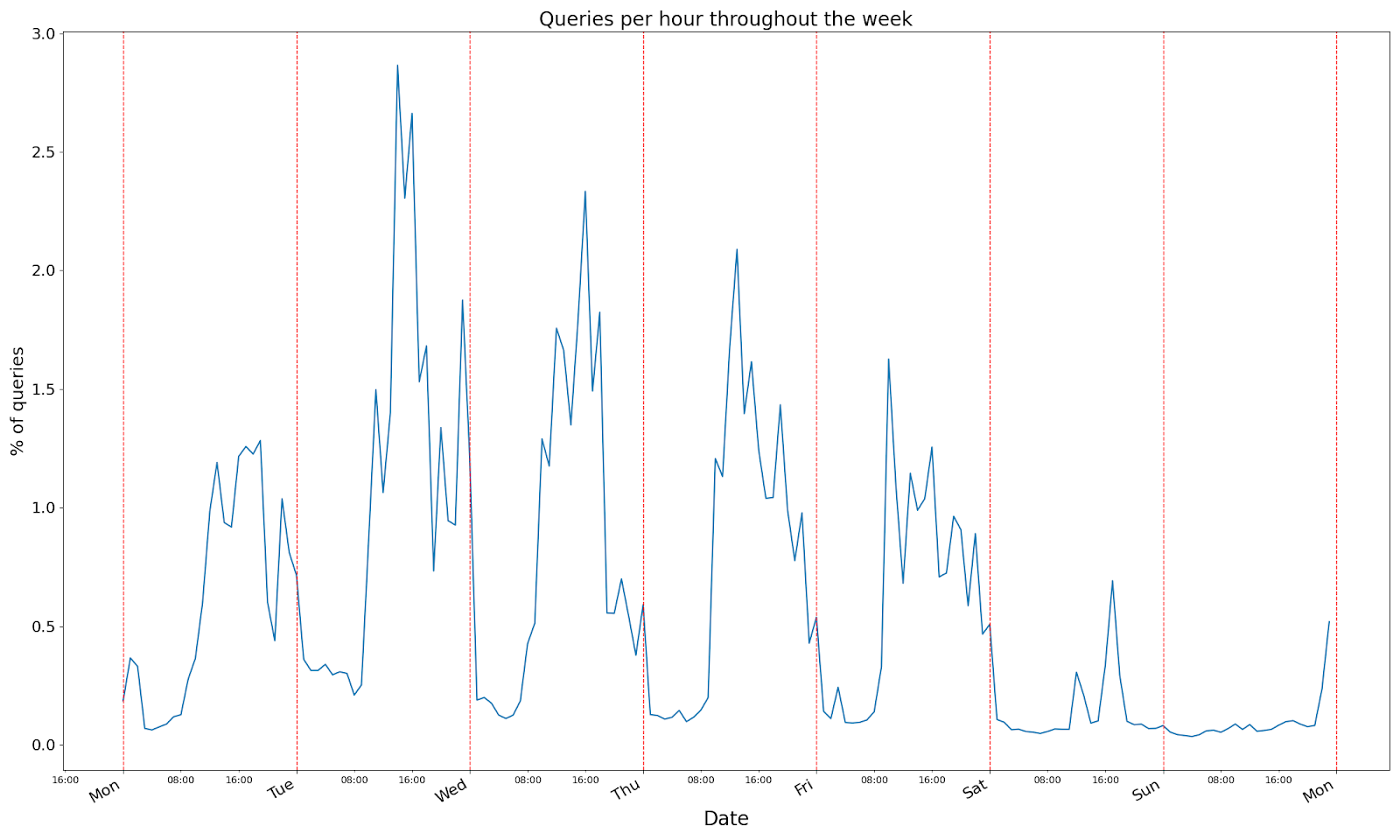
Of course our customers are based around the world (US heavy though) and so time is a little funny, but you can by-and-large assume that these are all local times. So we see a flurry of activity during the working week, a bit more in the evenings (the kind you’d see if we were based in NYC and some of our customers were based in San Francisco, for instance), and then much less in the middle of the night and at weekends. If you’ve ever worked for a business before, you’ve probably seen a graph like this.
Given we’re assuming OpenAI’s APIs are busiest during the working week, I guess we’d expect to see the tokens/second drop during the working week and spike elsewhere. The opposite graph I suppose.
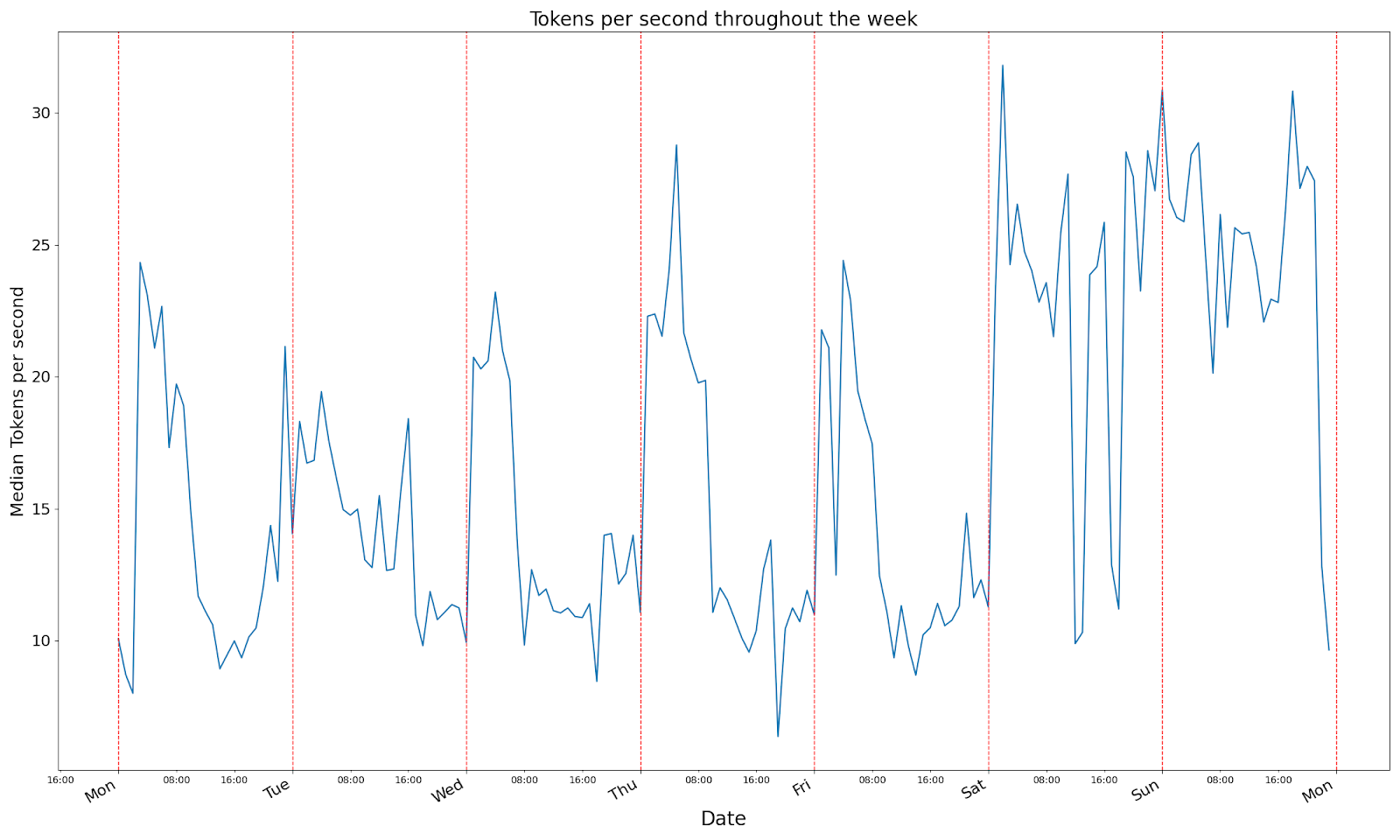
I’m going to say that we’re right. The drops kind of start where we’d expect, and the peaks kind of fall where we’d expect. I’d argue that the dips are more sustained later into the night, implying that OpenAI are probably bigger on the West Coast than we are. But…you know…that’s clearly true. I love implying things that are clearly true.
Looking at our log-linear model (and transforming hour into ‘day’, ‘evening’ and ‘night’, and transforming day of week into ‘weekday/weekend’. Basically just doing sensibleish things) we see that our LLM calls appear to be around 36% quicker on weekends and around 18% quicker during ‘unsociable hours’ (midnight - 8am NYC time).
Conclusion
If you care about speed:
- Fewer output tokens is pretty much the main game in town.
- Feel free to use plenty of input tokens to achieve that.
- However, be aware that each call has a start-up time that you’ll have to pay.
- GPT-Turbo-3.5 lives up to its name. If you care about speed, that’s a great model to use.
- If you can make your LLM calls outside the US work week, you probably should.
Footnotes:
[1] Given that the last blog post mentioned 500k LLM calls, you can get a rough idea of how quickly we’re growing based on these blogs. Turns out - really fast. If you too are hungry for LLM calls then why not come and work here? We’re hiring! [2] If you’d like me to go all sciencey on you then we’ll publish a paper based on this later where we go full sciencey. There’ll be equations and long words and all the kinds of things you, as science aficionados, go crazy for.