The AI Enterprise Adoption Curve: Lessons Learned So Far
September 20, 2024
At Credal, we’ve seen a lot of enterprises go through their AI adoption journey. We thought we’d write down some of our observations, to help answer questions like
- What does the typical AI enterprise adoption curve look like in regulated enterprises?
- What are the key use cases?
- What decisions do enterprises have to make and what should shape those decisions?
- What are the common sticking points / challenges enterprises face?
What Adoption Looks Like In Practice
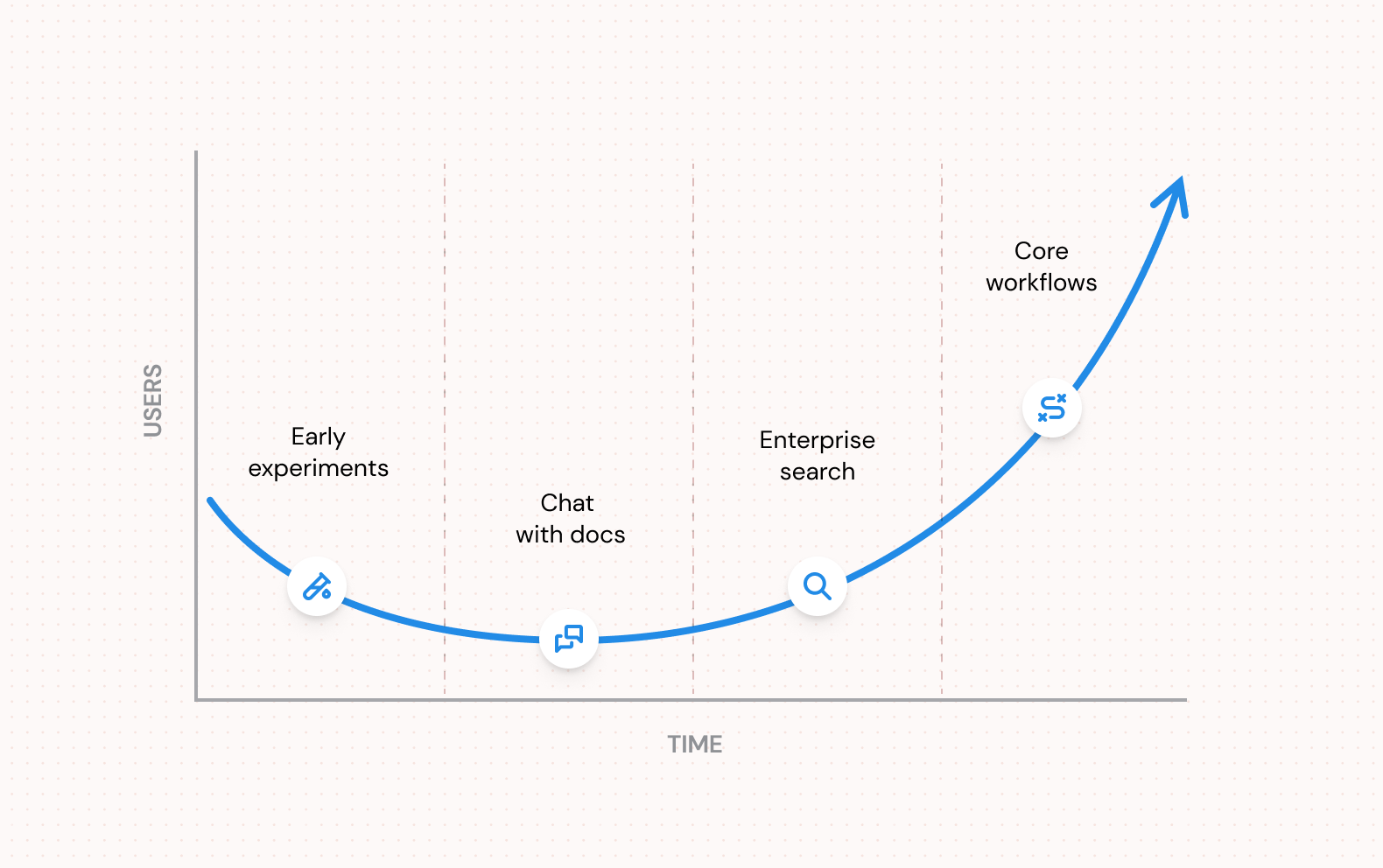
Let’s take the example of one of our customers, a background checking provider. This diagram shows a (schematic) representation of what their adoption cycle looked like:
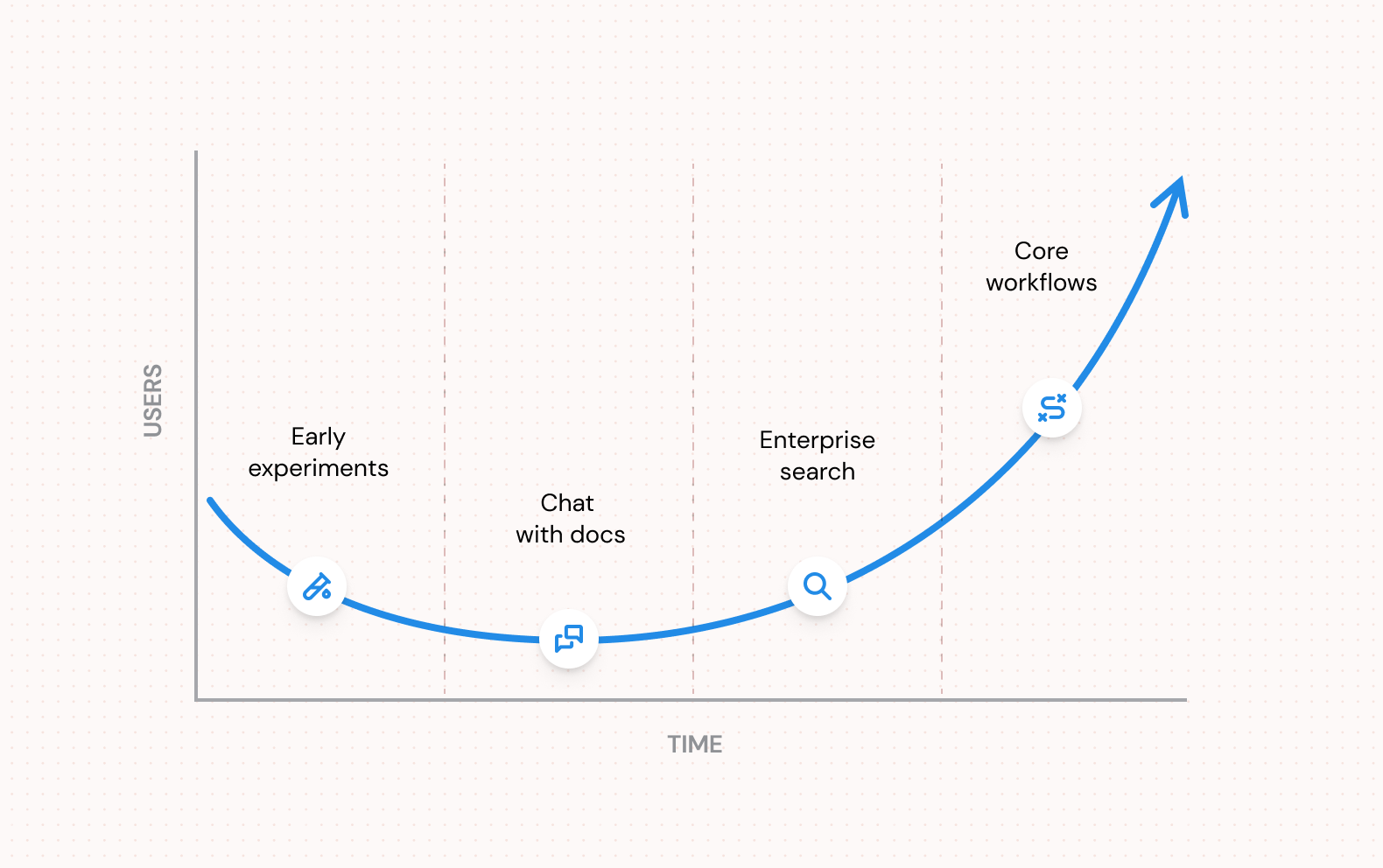
As you can see, there are four distinct stages here:
- Early experimentation (AI Taskforce)
- At this stage, the company is still evaluating what to do and the main goal is learning. There’s an early spike of excitement, hence lots of users, which quickly levels off.
- Early users include the CISO, AI Engineering Leads, some early adopters in Ops, after which a broader roll out may occur.
- Product used: vanilla AI Chat interface, no internal systems connection, such as ChatGPT, or Claude.ai
- Chat with Docs workflows
- This typically begins after a security audit has been passed and API integration has been set up. We can talk about two phases here:
- Chat on non-sensitive docs
- The company connects some lower-security documentation to the platform to be able to do basic “Chat with Docs” type workflows
- For example, you can ask questions about HR benefits, or search Github Issues
- Usage broadens somewhat, but still relatively narrow
- Chat on Internal/Sensitive Docs
- AI is more securely integrated into the company and this includes more sensitive docs (e.g. feedback/performance data, answering compliance questionnaires etc).
- The company is more comfortable with broadening AI usage, has a firm security policy/posture, has done relevant compliance checks, and has developed a rudimentary approach to access controls of which users can chat with what documents…
- Audit Logs, PII redaction and Acceptable Use Policies may start being enforced here.
- Enterprise Search
- Users can ask any question at all that draws on company data and automatically get a response from the most relevant specific company data.
- Access controls are rigorously enforced in near-real time across multiple sources
- Core Operations Workflows
- This is where the company begins to broaden beyond chat workflows and integrate AI into their core business processes.
- An example is the Gathering Feedback From Sales Calls workflow outlined here; another example is the AML/KYC workflow outlined here. Customer support, receipt matching and more.
- Agent workflows, copilots, and LLM orchestration come into play here.
- AI adoption broadens to beyond chat completion, including code execution, image generation, data retrieval and more
It begins with tremendous excitement, typically driven by executives or an AI task force. A handful of engineers experiment with open-source libraries, maybe try a vector database, and use third-party LLMs to prototype some workflows.
As soon as they want to move that prototype into production, several common challenges rear their head: privacy, security and compliance when integrating company data on the one hand, reliability and maintaining high quality performance over the long tail of production queries on the other.
Along the way, engineers encounter common challenges and questions, such as how best to implement ingestion and retrieval, whether fine-tuning actually helps, how the open source models compare to the proprietary models, which use cases will really work, should they try and stay model-agnostic or just go all in on OpenAI and on and on…
Other observations
What can we learn from this? In practice, enterprises seem to go with one of two AI strategies:
- Ban all external tooling and try provide a specific sandbox that employees can use;
- Provide a set of tools experimentally that are integrated with your data, and guidelines about appropriate use, and allow employees to discover use cases that work with those tools
The above path is a (successful) example of strategy #2.
With strategy #1, companies will usually end up building their own internal wrapper around Azure OpenAI. Most of these wrappers will be straightforward - an integration with Slack/Teams that automatically logs all queries into a central place where IT can see what’s going on.
Around 260+ companies chose to buy ChatGPT Enterprise, but many of the customers with Enterprise accounts *also* have their own wrappers built on Azure as well, since ChatGPT Enterprise costs a lot (our customers have been quoted $40-$60 per user per month) for access to Enterprise friendly Chat. Businesses doing this will find their employees able to quickly adopt classic “chat” workflows.
But ultimately, getting real value out of generative AI is all about equipping it with your data, so just giving your company a chat UI does not end up accelerating the business much: chat, by itself, is not that helpful.
With strategy #2, you get more experimentation, innovation, and discover the use cases that actually matter. But, as mentioned above, enterprises end up struggling with how to solve a whole host of issues that come with the generative AI territory. This is where many companies are today.
Over time you might see a few more sophisticated use cases; for example, using LLMs to accelerate KYC/ML processes, or parsing sales calls for customer feedback, or even end up having LLMs power core parts of your product.
In tech companies we’ve worked with, we tend to see roughly 50% of the organization using AI tooling within 8 weeks of adopting a tool, and 75% after a year, if things go well. We don’t have much data beyond a year since the technology is still so new, but it stands to reason that those numbers should just increase!
Key use cases
How have we seen AI deployed in the enterprise, in practice?
- Engineering:
- Engineering teams are using LLMs both to accelerate their own productivity, but also to deliver new types of features in the core products that they ship. Engineering productivity use cases focus on coding assistants, the most popular of which are Github Copilot, Sourcegraph Cody, and Codeium.
- But we’ve also seen Engineering teams use LLMs behind the scenes in core product functionality they provide to their customers: today, LLMs are driving things like receipt matching, automated employee background checks, and more.
- Operations and Finance:
- AI finds significant application in automating processes such as Anti-Money Laundering (AML) / Know Your Customer (KYC) and Transaction Monitoring checks, receipt matching, and accounting.
- Legal and HR:
- Contract negotiations
- Answering customer privacy and compliance queries
- Helping customers understand their HR benefits management.
- Marketing and Sales:
- Transcription, notes synthesis, and copywriting / comms workflows.
What decisions do enterprises have to make and what should shape those decisions?
1) Build vs. Buy?
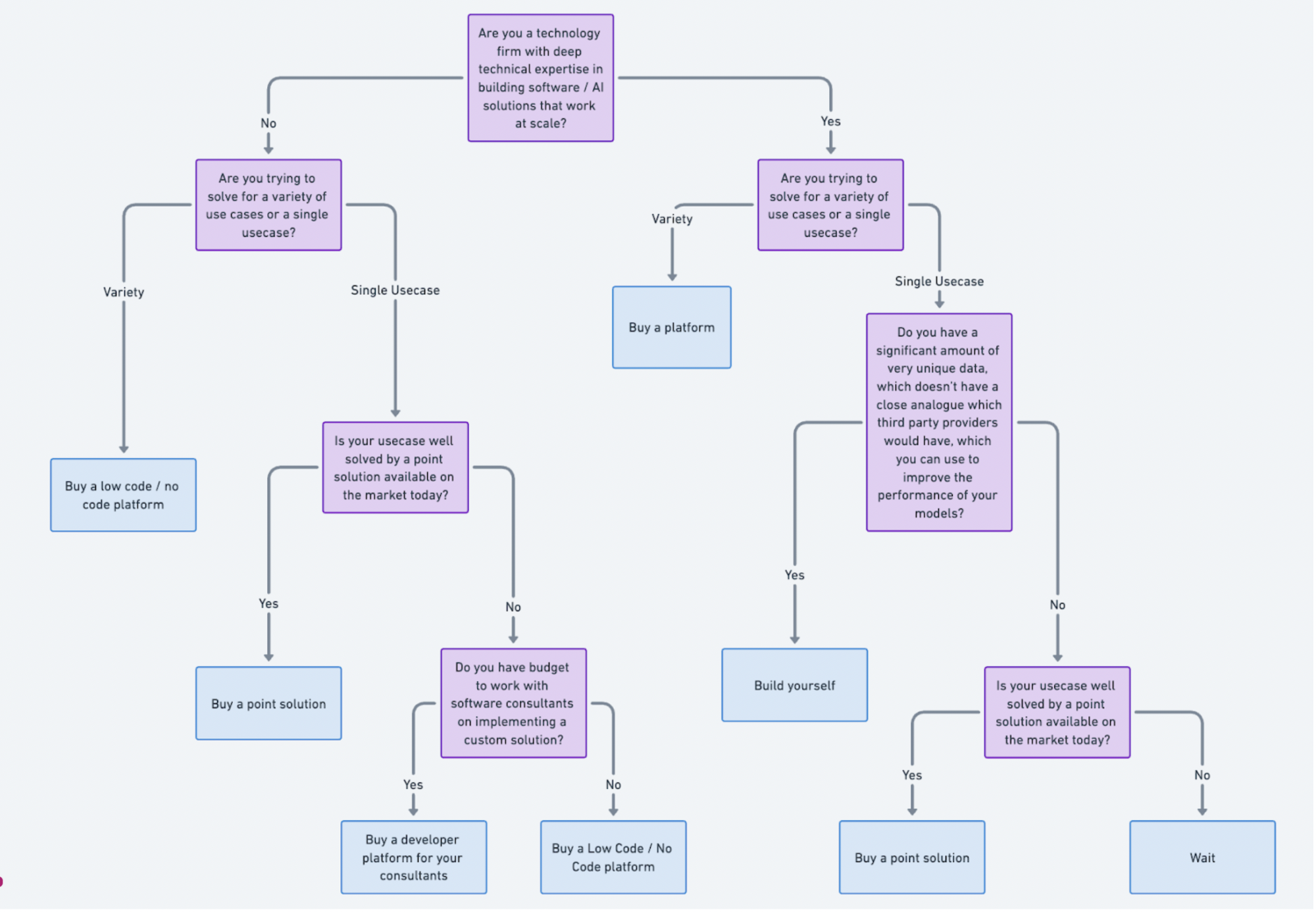
For core business processes, building in-house and owning the logic is key. A mature fintech firm might build its AML/KYC solutions to leverage its unique proprietary data; AML/KYC are core to the business. Or if you’re a social network, you want to own the logic for doing AI-driven recommendations, and it’s best to implement that yourself (using APIs as needed) rather than procuring this from a third-party.
It’s important to develop in-house expertise at AI; AI will be important, and having that expertise in your business is worth it; but point that effort at workstreams that are central/core to your business, and procure the rest.
It can seem highly appealing to build everything yourself, but we think that’s a mistake.
For certain products, like call transcription and coding assistants the market has very mature offerings at a variety of price ranges, and these will likely function at least as well as something you build in house, but for a fraction of the expense and available to use today, and putting immense developer resources behind building a coding assistant that can beat Github Copilot, Sourcegraph’s Cody, or Codium, is for most businesses unlikely to have positive ROI.
Similarly, if you want to have an enterprise search product at your company, it’s best to just go buy the one from the market, which has a range of mature options that can match most budgets. The maintenance burden of doing these in-house is usually too high.
Another way you can look at this is what stuff do I need control over vs. what can I delegate? For example, do I need an opinionated chunking strategy for my use case or can I leave it to the provider? What about reranking, retrieval strategy, etc?
Again, our view is that it depends on the use case: if core to your business, you need to own all the decisions; for basic use cases, just buy.
2) Platform vs. Point Solutions
We’re opinionated about this one: we think for most use cases you should buy a platform for your core AI workflows, not point solutions.
The problem with buying point solutions is that models update fast; what was the leading edge yesterday is not the leading solution today. So you need something that can adapt very fast, and is changeable and customizable to your needs.
Yes, there are some concrete point solutions that people should just buy, Github Copilot for coding is a good example, but for almost everything else you want to buy a platform that makes it easy to configure/build AI solutions for your business and takes care of the things you don’t want to worry about.
It’s also important that non-technical users can do them for themselves too; you don’t just want to buy a developer platform, you want something that everybody at your company can use to experiment.
3) Single LLM Provider vs. Multi-LLM Strategy
This is about whether you should go with a single provider, such as Google, OpenAI, or Anthropic; or whether you should diversify. In short, it’s important to have a multi-LLM strategy.
One interesting observation in this regard: smaller companies tend to be more willing to lock themselves into a single LLM provider. The larger/more sophisticated the company, the less likely they are to want to do that. Credal started its operations in the summer of 2022. At the time, we felt Anthropic’s Claude 1.0 was the best available mode (ChatGPT and GPT-4 had not yet been released).
A related question is whether to go closed or open source.
The LLM ecosystem is evolving fast so this could change anytime, but for now it seems that the leading frontier models, such as GPT-4 and Claude 3, are still better at the most complex/intelligence-requiring tasks, such as higher level reasoning and coding. Call these 90th-100th percentile tasks. For example:
- If you want your LLM to be able to read a Github Issue and produce a Pull Request that solves it, you probably want something that’s of this caliber.
- We find these models are better at writing and more sophisticated synthesis tasks.
For the remainder of tasks that fall into the “0th-90th percentile”, it can be cheaper to use a leading open source model such as Mixtral-8x7B, LLaMA 2, or similar; these can be fine-tuned to be as good or even better than GPT3.5, making them great for simpler cognitive tasks such as classifying, tagging, or other such workflows. For example, the receipt matching workflow at Ramp is done using open source models. And for more basic ‘coding’ type tasks, such as making SQL queries, it is worth noting that Open Source Text to SQL models, such as Defog, are actually outperforming GPT-4 on benchmarks.
It’s important to work with a platform (such as Credal) that is model-agnostic and allows you to route through different providers. This has the benefit of avoiding lock-in.
What are the challenges of adoptions / common sticking points?
We’ve seen a good number of challenges to AI adoption in the enterprise. These ones stand out:
1/ Data Security
Data Security is the single biggest barrier to enterprise adoption of AI.
Most of the public facing end-user tools out there do not provide sufficient visibility for IT into what end users are doing. The fear that end users are copy-pasting company data, including customer sensitive information and PII, into these tools is very real and causes many organizations to either ban or block all usage.
For folks considering building their own wrapper around ChatGPT, as ChatGPT’s capabilities have expanded to include things like web search and code interpreter over time, the concern evolves into whether an internal wrapper solution will stop people from logging into ChatGPT at all, e.g. from their personal devices.
Enterprises don’t want to appear employee-hostile or reduce productivity by banning a useful tool, but the inability to implement something that actually works well for the company kills the golden goose.
2/ Use case discovery and value quantification
Understanding what use cases are actually valuable for the business is the second biggest barrier to entry, especially at larger organizations.
While notions like “generative enterprise search” sound exciting, the ROI can be unclear. At scale, the costs for AI tools can add up, making it difficult to justify these expenses across the organization, especially with popular tooling being priced at $20-$60 per seat. On top of that, there’s a concern that the “hype” outpaces the actual utility of these tools.
There is also the related problem of executives who do not necessarily fully grasp the capabilities of a technology or how it can fit into the workflows of employees making overly specific decisions about what workflows should be allowed / implemented. Ultimately, this has to be addressed by allowing employees to build their own tooling on top of a platform and rapid experimentation and iteration based on what works.
3/ Duplicate use cases and data fragmentation
Another issue blocking enterprises from rolling these tools out is the concern that many different teams will build roughly the same workflows and use cases in different tools, creating a fragmented data landscape and additional cost. Again, this is why we are bullish on a platform versus a patchy landscape of point solutions.
4/ Legal and regulatory barriers
Concerns over the NY AI act, EU AI act, and the extent to which things are properly compliant. There is also a general lack of understanding of what these laws really entail. It can be helpful to work with a platform that guarantees compliance with the regulations, but there’s also no substitute for in-house expertise.
5/ Human Resources challenges and training
AI can be a scary technology for some companies, especially those with less tech savvy employees. Employees worry adoption of tools may leave them vulnerable to replacement by AI, and executives worry about the morale impacts and the learning and development programs required to actually equip employees with the confidence and skills required to use the tools.
Its important for employees to understand that AI is in many ways a lot like every other technology: those that learn to use it effectively will have their productivity dramatically increased, ultimately helping them be more succesful at their organization. By contrast, those who shy away from using AI, may risk finding themselves at risk not from the technology itself, but rather, from colleagues that have more effectively incorporated it into their workflows. Building a deep understanding of AI today is a great way for employees to position themselves to be ever more valuable in the labour market over the next decade.
6/ Unpredictability in RAG + difficulty of debugging
Search use cases are hard to productionize, debugging is difficult, infrastructure, governance, access management and such are super complicated components. Evaluation of LLM based systems are notoriously difficult, meaning that minor-seeming changes to a critical prompt can cause major changes in the behavior of the overall system. This makes companies understandably wary of deploying them into critical workflows without extensive testing, governance and baked in version control.
That’s all! In part 2 of this post, we’ll follow up with a more specific guide to the AI/LLM space, and an RFP guide that goes through specific features you should be familiar with and look for when it comes to generative AI in the enterprise. This includes questions like:
- Features, functionality and APIs
- Security and compliance
- Cost
- Key players / a map of the space
If you’re in a regulated industry or want advice on dealing with these issues, or want to arrange a demo of our platform, feel free to contact us and we’d be happy to help: founders@credal.ai


