
What is Agent Sprawl?
February 03, 2026
One of the biggest challenges of scaling AI at enterprises is the risk of agent sprawl. Agent sprawl is a phenomenon when enterprises end up producing dozens, if not hundreds, of AI agents without a centralized way of organizing them. Agent sprawl creates a plethora of problems: (a) IT lacks oversight, making it difficult to ensure agents meet compliance and security prerogatives (e.g. SOC 2, customer contracts, etc.), (b) redundant agents are built by siloed teams (e.g. engineering, customer success, data science etc.), and (c) agents cannot easily communicate with each other since they live on separated systems.
The security risk is particularly daunting. Agents handle sensitive data (e.g., customer records, company intel, etc.) and can carry out destructive actions without appropriate checks in place. They could also easily exfiltrate data whenever they violate the lethal trifecta, a set of common conditions described in a famous Simon Willison post. These risks are well known to security researchers, but most enterprise teams aren’t cognizant of them or possess the skills to prevent them. Instead, safeguarding data is the role of the IT department; unfortunately, with agent sprawl, the IT department easily loses oversight of all the company’s agents in existence.
The solution, however, isn’t to reduce the dependency on agents. Agents can be extremely useful across an organization: they can handle recruitment, migrate data, merge pull requests, dispatch cold emails, and many more otherwise time-consuming tasks. Instead, organizations need to employ an agent registry to organize their agents. An agent registry is a centralized “phone book of sorts” for AI agents: it enables agents to be tracked, filterable, and easily exposed to enable agent-to-agent work. Most importantly, it provides an IT department with a single source of truth, making it easy to determine what agents have access to what.
To discuss this problem at length, I’ll start by detailing the risks of agent sprawl. Then, I’ll dive into why an agent registry is the only scalable fix.
At scale, the simplest agent is still complex
One of the key points that I want to fixate on is how hard it is to build a single agent at scale. When building agents for a side project or a smaller company, it might be as easy as using OpenAI’s AgentKit or Claude Agents. Agents are just programs that use an LLM as an underlying brain; from a ten-thousand-foot view, they carry the same needs as any other program.
However, the issue is that agents are non-deterministic. They can make mistakes, hold onto information via memory, and exfiltrate data to potential attackers. Accordingly, they need to be treated the same as humans, they need to have access restricted, be monitored for mistakes, and be subject to any compliance policy that safeguards data.
Consider a large retail company that wanted a basic agent to summarize daily store-level sales updates and email them to district managers. On paper, it might seem trivial: pull data from the BI warehouse, generate a summary, and send an email. However, the agent must rate-limit access to the data warehouse, follow encryption rules for handling financial records, implement retention controls for email history, and establish guardrails to avoid accidentally emailing the wrong distribution list. Legal also requires the agent to redact customer identifiers in summaries, and Compliance requires real-time logging of all outbound messages. It’s no longer a five-minute AI agent project, it quickly balloons into a multi-team engineering effort as even the simplest agent might touch sensitive data and risk exfiltrating information.
These complex requirements are why many enterprises fail to deploy agents to production. It’s also why there are copious examples of security breaches at the hands of agents. Without the right care, agents could introduce as many hazards as they provide benefits.
Agent sprawl compounds the root issues
Agent sprawl compounds all of the challenges of building agents. As more and more agents emerge, produced by disconnected teams, the likelihood of a security breach and compliance violation skyrockets. It’s simple math: if the blanket odds of a security breach are ~1% per agent, then an enterprise with 100+ agents has worse than coin-flip odds of an incident!
This massive risk is what has pushed builders to create products tackling AI governance and agent containment. However, the holistic issue with sprawl is visibility. If agents aren’t organized in a single location, it’s impossible to roll out governance initiatives targeting an agent’s access or to gather telemetry.
Agent sprawl hampers agent-to-agent work
Agents have the capacity to work together; agents can interact with other agents to solve problems in tandem. For instance, a common example is a pull request agent. A single coding agent might monitor pull requests, scan the codebase, and make comments. However, it might need to invoke a separate agent that’s designed to dispatch notifications to Slack, developer emails, and developer devices. Of course, a single agent could solve all of these problems. Still, it’s far more efficient if one agent specializes in developer communications and another agent specializes in pull requests, it minimizes the context required for agents and allows them to learn behaviors specific to their domains.
Agent sprawl is the consequence of a lack of direction
Agent sprawl is going to naturally occur in enterprises that don’t have a dedicated system for creating, listing, and monitoring agents. Every team across the organization, from engineering to marketing to customer success, is looking to employ AI to improve their efficiency. Instead of waiting for systems to be built, teams will use products like n8n, Gumloop, and AgentKit to design their own agents, even at the risk of violating key security tenets and compliance rules.
For example, imagine a Fortune 100 recruiting organization. Individual recruiters might start experimenting with AI sourcing agents to scrape LinkedIn profiles, schedule interviews, and pre-screen applicants. Within weeks, the IT team might identify 14 separate sourcing agents, each storing candidate PII differently and each with its own set of permissions. Not only did that create duplicate outreach and contradictory messaging to candidates, but several agents might retain resumes past the retention period, inadvertently creating a GDPR violation risk.
Accordingly, IT needs to be proactive about providing the structure to build AI agents so that teams build with registries in mind.
The Solution: Agent Registries
An agent registry is a centralized hub or catalog that stores information about a company’s AI agents. An agent registry allows for easy discovery, management, and governance of AI agents.
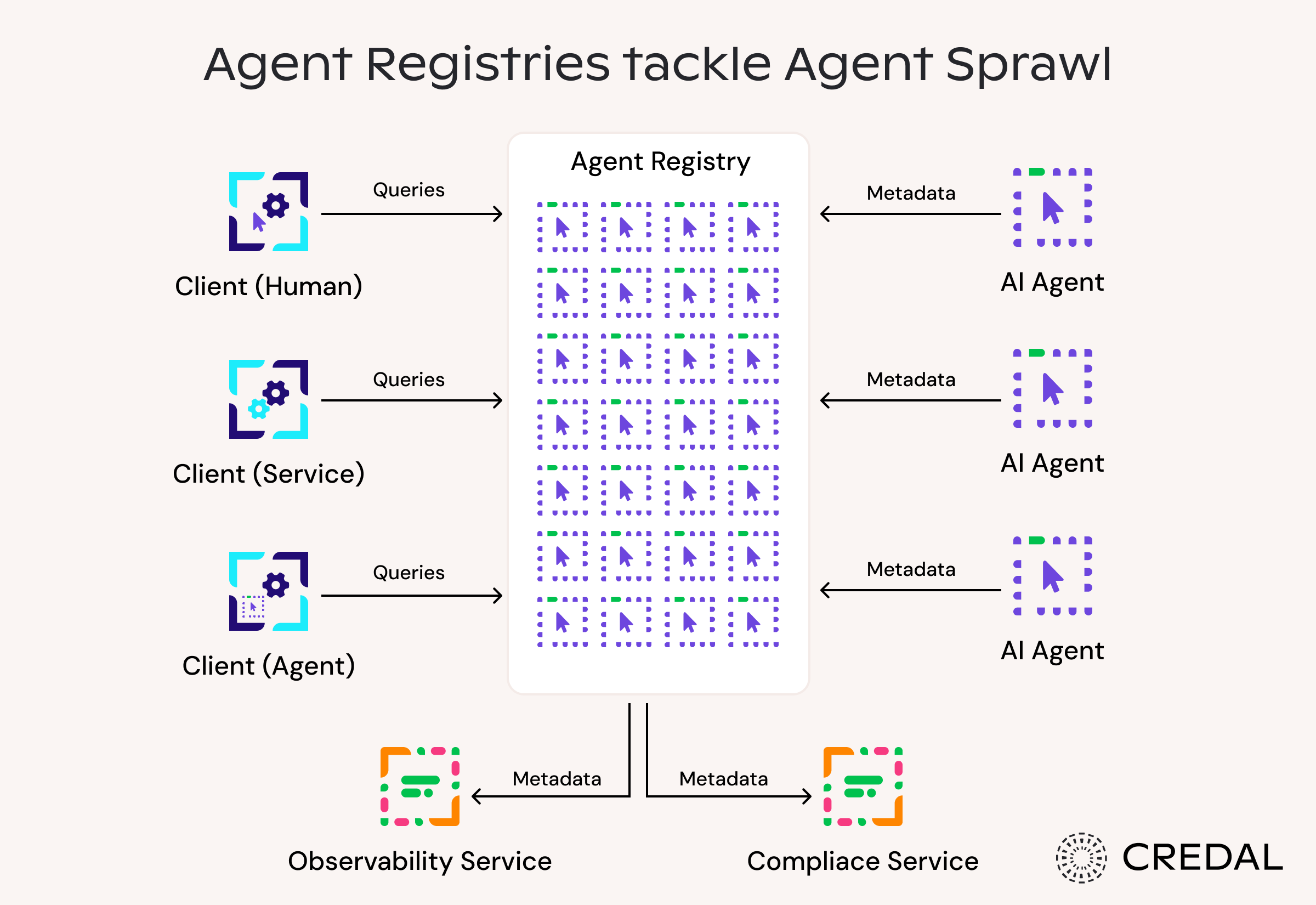
Agent registries have often been likened to phone books, as they provide information about the agent’s capabilities as well as how to connect with them. It’s an apt analogy, but it undersells the biggest benefit of agent registries: it provides a central place for IT departments to manage access and track agent actions.
Because agent registries are an independent surface, they can also subject agents to requirements that accomplish certain IT requirements. For instance, the IT department might want to ensure that agents are constantly available so that neither users nor programs interact with agents undergoing an outage. To solve this, the IT department could configure an agent registry to require agents to send a heartbeat health check so that the registry could ensure that the agent is online.
Similar requirements could be extended to consolidating information about the agent’s access (e.g. ACL or roles in an RBAC schema), any authentication credentials, supported data types, logs of external actions, etc.
In other words, the agent registry not only centralizes data about agents, but sets the standard for how agents are built across the entire organization. That way, when compliance drafts SOC 2 commitments or GDPR disclosures, they can align them with the registry’s requirements, trusting the registry to enforce those requirements on any listed agent. Additionally, the agent registry makes it easy for teams to browse available agents and avoid redundant work, thereby directly minimizing agent sprawl.
Finally, agent registries aid the most common agent user: other agents! With a registry, agents can programmatically search, discover, and employ other agents to carry out tasks. For example, a compliance agent might discover an agent who’s an expert on the company’s Salesforce to ensure that a certain customer record isn’t being leaked.
A Closing Thought: Not All Registries are the Same
There have been a few companies that have taken a stab at building agent registries. Some are siloed to a single cloud ecosystem and set of ML models, for example, Microsoft Agent 365 or Google’s Agentspace. However, given that enterprise teams often use multiple model providers, using a model-agnostic registry like Credal is a better route for building scalable agents.
Discover more about Credal by booking a demo today.


